Python 提供了很多MPI模块写并行程序,其中 Spinning UP项目主要使用了mpi4py 这个库来实现并行强化学习。因此,事先掌握这个库的用法有助于源码理解或自己写项目。
什么是MPI
MPI的全称是Message Passing Interface,即消息传递接口。
- 它并不是一门语言,而是一个库,我们可以用Fortran、C、C++结合MPI提供的接口来将串行的程序进行并行化处理,也可以认为Fortran+MPI或者C+MPI是一种再原来串行语言的基础上扩展出来的并行语言。
- 它是一种标准而不是特定的实现,具体的可以有很多不同的实现,例如MPICH、OpenMPI等。
- 它是一种消息传递编程模型,顾名思义,它就是专门服务于进程间通信的。
MPI的工作方式很好理解,我们可以同时启动一组进程,在同一个通信域中不同的进程都有不同的编号,程序员可以利用MPI提供的接口来给不同编号的进程分配不同的任务和帮助进程相互交流最终完成同一个任务。就好比包工头给工人们编上了工号然后指定一个方案来给不同编号的工人分配任务并让工人相互沟通完成任务。
由于CPython中的GIL的存在我们可以暂时不奢望能在CPython中使用多线程利用多核资源进行并行计算了,因此我们在Python中可以利用多进程的方式充分利用多核资源。Python中我们可以使用multiprocessing模块中的pipe、queue、Array、Value等等工具来实现进程间通讯和数据共享,但是在编写起来仍然具有很大的不灵活性。而这一方面正是MPI所擅长的领域,因此如果能够在Python中调用MPI的接口将使事情变得非常容易。
mpi4py是一个构建在MPI之上的Python库,主要使用Cython编写。mpi4py使得Python的数据结构可以方便的在多进程中传递。mpi4py是一个很强大的库,它实现了很多MPI标准中的接口,包括点对点通信,组内集合通信、非阻塞通信、重复非阻塞通信、组间通信等,基本上能想到用到的MPI接口mpi4py中都有相应的实现。
在Windows中的安装
https://docs.microsoft.com/en-us/message-passing-interface/microsoft-mpi?redirectedfrom=MSDN下载微软官方的MPI程序,下载那个exe就行了,管理员身份点击安装。cmd命令行中输入mpiexec能显示相关信息即可。
pip install mpi4py安装Python第三方库以支持MPI环境。测试:
编写脚本如下
1
2
3
4
5# helloMPI.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
print("hello world from process ", rank)命令行执行
1
mpiexec -n 5 python helloMPI.py
输出如下
1
2
3
4
5hello world from process 2
hello world from process 0
hello world from process 4
hello world from process 1
hello world from process 3
mpi4py使用
基本
from mpi4py import MPI将会为脚在MPI环境中注册MPI.COMM_WORLD访问进程通信域MPI.COMM_WORLD.Get_rank()获取当前进程编号MPI.COMM_WORLD.Get_size()获取总进程数
点到点通信
COMM_WORLD.send(data, process_destination): 通过它在rank编号来区分发送给不同进程的数据COMM_WORLD.recv(process_source): 接收来自源进程的数据,也是通过rank编号来区分的
1 | # p2p.py |
命令行执行:
1 | mpiexec -n 9 python p2p.py |
可能的结果:
1 | my rank is : 3 |
整个过程分为两部分,发送者发送数据,接收者接收数据,二者必须都指定发送方/接收方。COMM_WORLD.send() 和 COMM_WORLD.recv() 函数都是阻塞的函数。他们会一直阻塞调用者,直到数据使用完成。
broadcast(广播)
在并行代码中,我们会经常需要在多个进程间共享某个变量运行时的值,为了解决这个问题,使用了通讯数。举例说,如果进程0要发送信息给进程1和进程2,同时也会发送信息给进程3,4,5,6,即使这些进程并不需要这些信息。
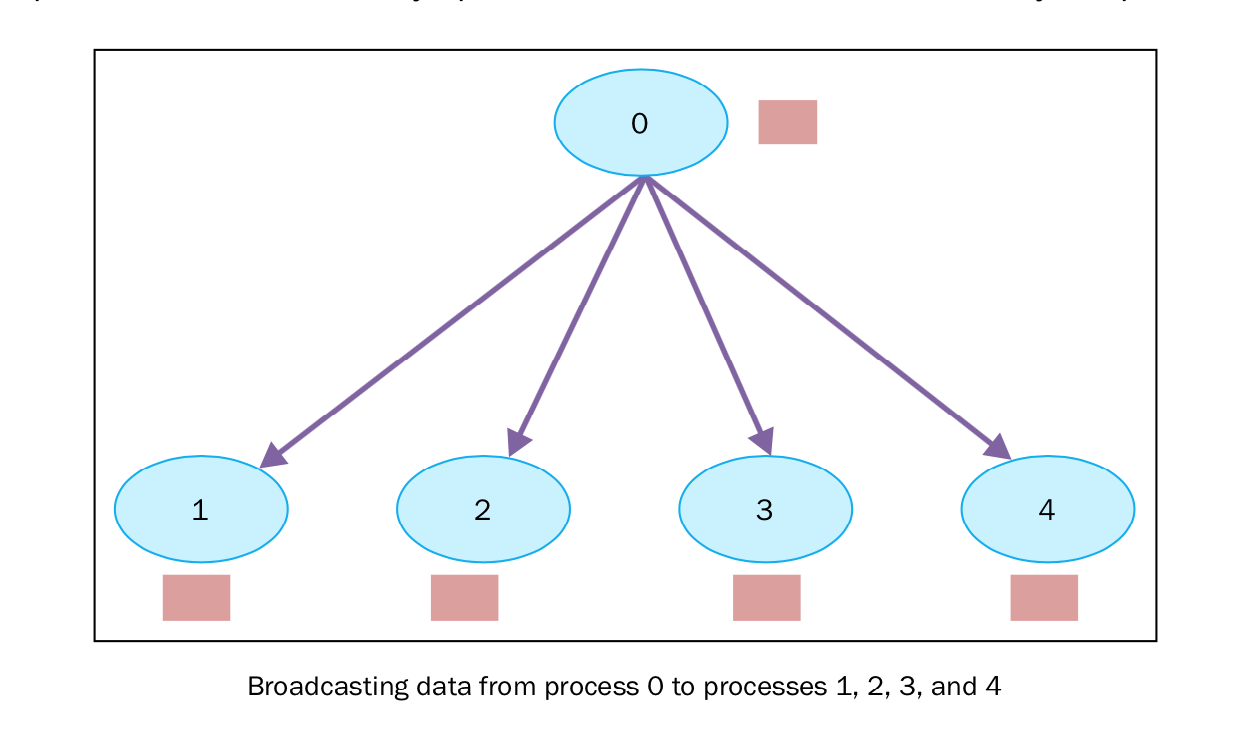
mpi4py 模块通过以下的方式提供广播的功能:
1 | buf = COMM_WORLD.bcast(data_to_share, rank_of_root_process) |
这个函数将root消息中包含的信息发送给属于通讯组其他的进程,每个进程必须通过相同的 root 和 COMM_WORLD.bcast 来调用它。
1 | # broadcast.py |
命令行执行:
1 | mpiexec -n 10 python broadcast.py |
可能的结果:
1 | process = 0 variable shared = 100 |
scatter(分散)
scatter函数和broadcast很像,但是有一个很大的不同, MPI.COMM_WORLD.bcast 将相同的数据发送给所有在监听的进程, MPI.COMM_WORLD.scatter 可以将放在数组中的数据,分别散布给不同的进程。下图展示了scatter的功能:
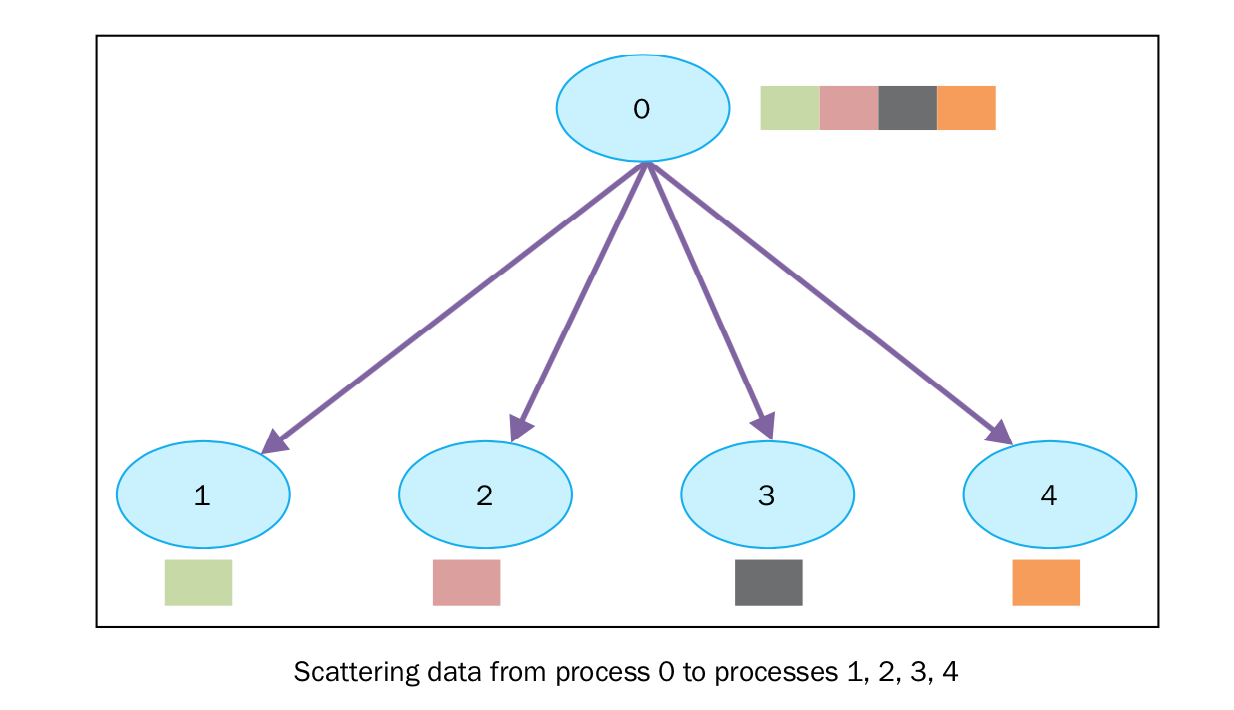
注意,分散时,rank号与数组下标号是对应的,即数组长度必须等于进程数。
mpi4py 中的函数原型如下:
1 | recvbuf = comm.scatter(sendbuf, rank_of_root_process) |
在下面的例子中,我们将观察数据是如何通过 scatter 发送给不同的进程的:
1 | from mpi4py import MPI |
运行代码的输出如下:
1 | C:\>mpiexec -n 10 python scatter.py |
gather(聚合)
gather 函数基本上是反向的 scatter ,即手机所有进程发送向root进程的数据。 mpi4py 实现的 gather 函数如下:
1 | recvbuf = comm.gather(sendbuf, rank_of_root_process) |
这里, sendbuf 是要发送的数据, rank_of_root_process 代表要接收数据进程。
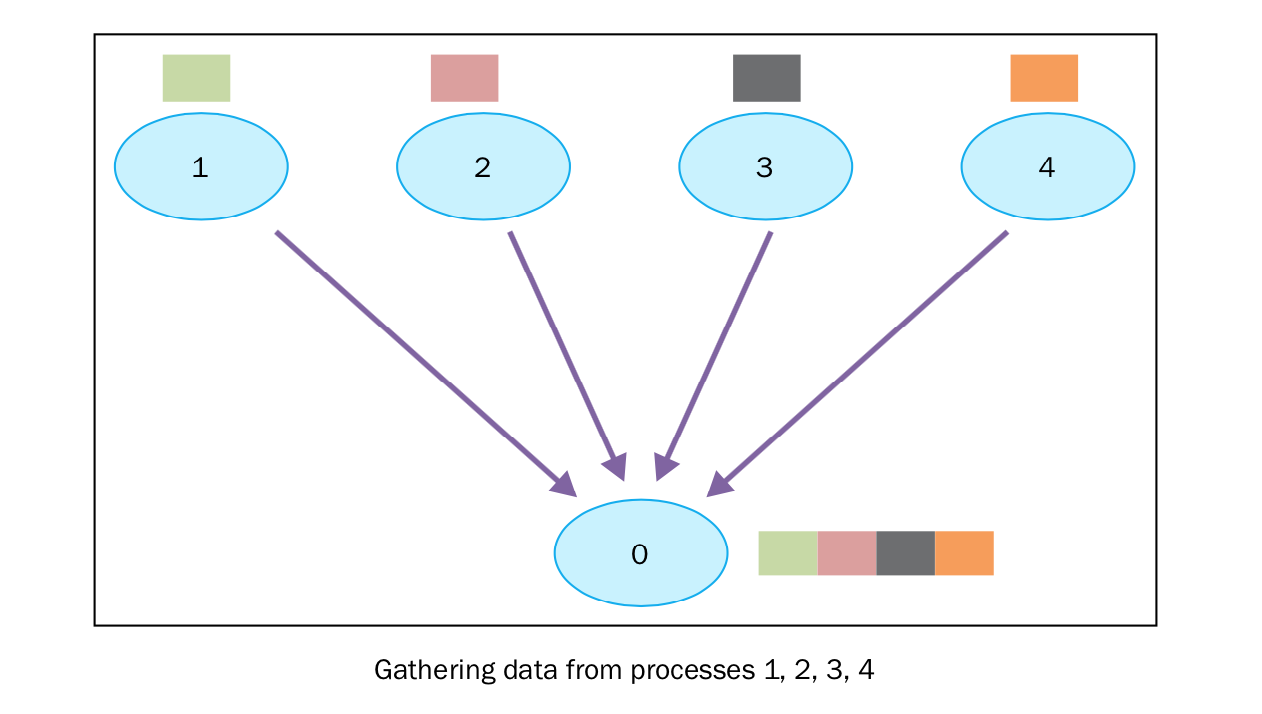
在接下来的例子中,我们想实现上图表示的过程。每一个进程都构建自己的数据,发送给root进程(rank为0)。
1 | from mpi4py import MPI |
最后,我们用5个进程来演示:
1 | C:\>mpiexec -n 5 python gather.py |
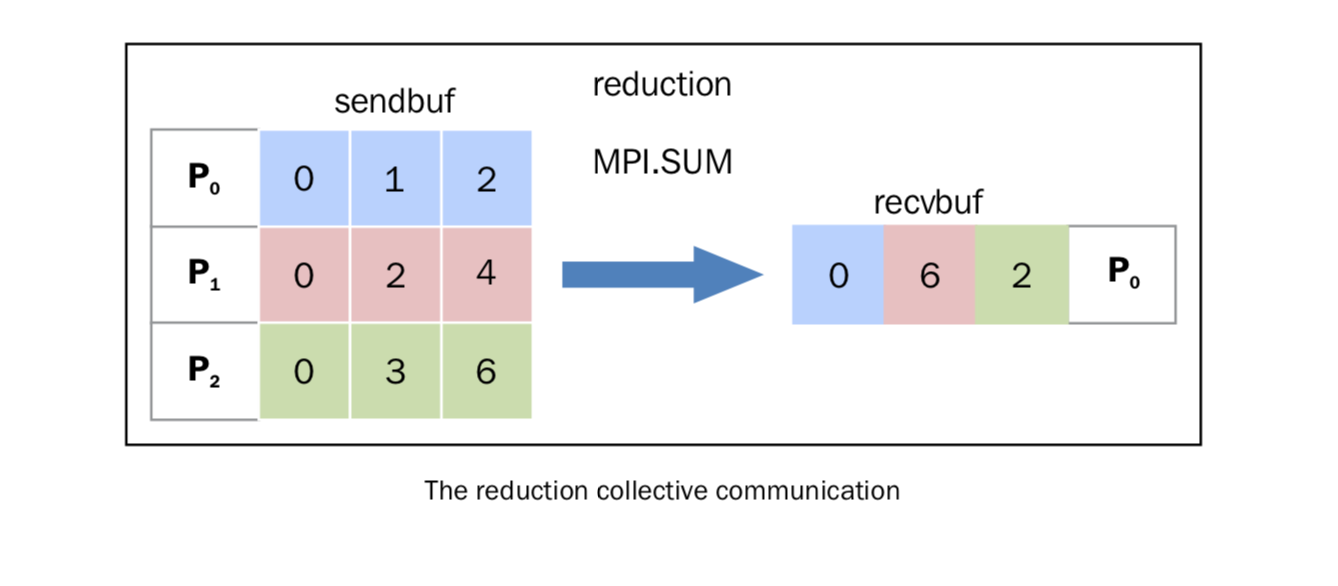
reduce
同 comm.gather 一样, comm.reduce 让root进程接收一个数组,但是不同的是,每个进程都维护一个数组,然后所有进程sendbuf第i位元素参与指定操作,而后赋给root进程recvbuf中的第i位。
在 mpi4py 中,我们将简化操作定义如下:
1 | comm.Reduce(sendbuf, recvbuf, rank_of_root_process, op = type_of_reduction_operation) |
这里需要注意的是,参数 op 代表你想应用在数据上的操作, mpi4py 模块代表定义了一系列的操作,其中一些如下:
MPI.MAX: 返回最大的元素MPI.MIN: 返回最小的元素MPI.SUM: 对所有元素相加MPI.PROD: 对所有元素相乘MPI.LAND: 对所有元素进行逻辑操作MPI.MAXLOC: 返回最大值,以及拥有它的进程MPI.MINLOC: 返回最小值,以及拥有它的进程
现在,我们用 MPI.SUM 实验一下对结果进行相加的操作。每一个进程维护一个大小为 3 的数组,我们用 numpy 来操作这些数组:
1 | import numpy |
我们用通讯组进程数为 3 来运行,等于维护的数组的大小。输出的结果如下:
1 | C:\>mpiexec -n 3 python reduction2.py |
原理图示:
SpinningUp中的具体使用
mpi_fork函数
代码位置:spinup/utils/mpi_tools.py
作用:退出当前脚本主进程,并在MPI环境中启动n个当前脚本进程
注意:
如果报错“hp, ht, pid, tid = _winapi.CreateProcess(executable, args, FileNotFoundError: [WinError 2] 系统找不到指定的文件。”可以参看https://www.jianshu.com/p/fbc31e1cc32a
如果windows下使用的是mpich的MPI实现方式,则
args = ["mpirun", "-np", str(n)]需要改写成args = ["mpiexec", "-np", str(n)]openmpi还支持绑定到核心机制,可能会更稳定。
1 | from mpi4py import MPI |
allreduce函数
代码位置:spinup/utils/mpi_tools.py
作用:对所有进程的sendbuf做统一约归,并赋值给每一个进程的recvbuf。不再像reduce那样,有root的概念。
注意:
实质就是MPI.COMM_WORLD.Allreduce。大写表示可以对numpy数组等数据类型执行操作,小写只能python内置类型。
参数因包括
snedbufrecbuf和op,具体参见reduce。```python # 全约归,不再有root的概念,每个进程的recvbuf都是一样操作、一样结果的 def allreduce(*args, **kwargs): return MPI.COMM_WORLD.Allreduce(*args, **kwargs)
1
2
3
4
5
6
7
8
9
10
11
12
### mpi_op函数
在allreduce的基础上封装的操作的基本函数,主要是为了统一标量和序列操作。
```python
def mpi_op(x, op):
x, scalar = ([x], True) if np.isscalar(x) else (x, False)
x = np.asarray(x, dtype=np.float32)
buff = np.zeros_like(x, dtype=np.float32)
allreduce(x, buff, op=op)
return buff[0] if scalar else buff
如果指定op=MPI.SUM,那么就是后面定义的mpi_sum(x)函数,诸如此类,都是mpi_op的具体化。
最后一个函数mpi_statistics_scalar是为了获取进程所有数组的mean和std,如果设置可选参数为True,还能获得所有数组元素的最大最小值。
结合pytorch的一些操作
1 | #所有进程梯度信息取平均 |